เรียนรู้เทคนิคของ AI ในการทำ machine learning
Phantom จาก DJI พลิกวงการโดรน
January 14, 2021AI โดรนกับการพัฒนาล่าสุด
February 4, 2021เรียนรู้เทคนิคของ AI ในการทำ machine learning
ทำความรู้จักกับ semi-supervised machine learning
Machine learning มีความสามรถในการแยกแยะรูปภาพและข้อมูลต่างๆที่โปรแกรมคอมพิวเตอร์ปกติทำไม่ได้ แต่ก่อนที่ machine learning จะสามารถทำสิ่งเหล่านี้ได้ เราจำเป็นที่จะต้องใช้ข้อมูลที่ได้รับการ “ระบุค่า (label)” ว่าข้อมูลแต่ละตัวคืออะไร จำนวนมากในทำ machine learning ซึ่งขั้นตอนการระบุค่าข้อมูลเหล่านั้นเป็นขั้นตอนที่ใช้เวลาและต้องใช้มนุษย์ในการทำหน้าที่นี้
ในความเป็นจริงการระบุค่าที่ว่านี้เป็นสิ่งที่สำคัญมากสำหรับ machine learning จนทำให้มีบริษัทสตาร์ทอัพจำนวนมาก อย่าง Amazon’s Mechanical Turk, LabelBox, ScaleAI, และ Samasource ที่สร้างแพลตฟอร์มสำหรับการจัดการข้อมูลสำหรับ machine learning ขึ้นมา
ทว่าในบางครั้งเราก็ไม่จำเป็นต้องระบุข้อมูลทุกตัวเพื่อการจัดกลุ่มเสมอไป เพราะ semi-supervised learning เป็นอีกวิธีที่จะจัดชุดข้อมูลได้ด้วยตัวเอง
Supervised vs unsupervised vs semi-supervised machine learning

supervised machine learning จำเป็นต้องระบุข้อมูลทั้งหมดได้ เพื่อสร้างฐานข้อมูลให้ AI วิเคราะห์และทำงานได้ โดยวิธีนี้มักถูกใช้เพื่อแยกแยะรูปภาพ (image classification), ระบุหน้าตา (face recognition), ประเมินผลการขาย, ทำนายลักษณะลูกค้าที่กำลังจะยกเลิกบริการ และตรวจหา spam
ในทางกลับกัน Unsupervised learning ถูกใช้เพื่อจัดการกับชุดข้อมูลที่ไม่สามารถระบุได้แต่ต้องการที่จะมองหารูปแบบ (pattern) โดยมากจะใช้ในการจัดกลุ่มลูกค้า การตรวจจับเหตุการณ์ที่คาดว่าจะผิดปกติ และการแนะนำ content ใกล้เคียง
ส่วน Semi-supervised learning เป็นการทำนายว่าข้อมูลจะอยู่กลุ่มไหน ซึ่งแปลว่าต้องใช้ supervised learning algorithm ในการทำงาน แต่ไม่มีความจำเป็นต้องระบุได้ว่าข้อมูลทั้งหมดคืออะไรบ้าง เช่นเดียวกับ unsupervised machine learning
Semi-supervised learning กับการ clustering และ classification
วิธีที่จะสามารถทำ semi-supervised learning ได้คือการรวมการจัดข้อมูลแบบ clustering และ classification เข้าด้วยกัน โดย Clustering algorithms คือการรวมชุดข้อมูลที่คล้ายคลึงกันให้เป็นกลุ่ม ซึ่งช่วยให้สามารถหาความคล้ายกันของข้อมูลนั้นๆและเอามาระบุได้ภายหลังว่าข้อมูลแต่ละชุดคืออะไร ก่อนที่จะเอาไปจัดประเภทแบบ classification ในภายหลัง
ตัวอย่างเช่น ถ้าอยากฝึกให้คอมพิวเตอร์สามารถอ่านตัวเลขที่เขียนด้วยลายมือ แต่มีชุดข้อมูลเป็นภาพของตัวเลขจำนวนมาก การเลือกวิธีระบุว่าภาพของเลขแต่ละตัวมีค่าเท่าไหร่ด้วยมนุษย์คงไม่ใช่ทางเลือกที่ดี เราจึงควรใช้ semi-supervised learning เพื่อสร้างโมเดลสำหรับ AI ขึ้นมา
K-means เป็นวิธีที่ง่ายและได้ผลดีสำหรับการทำ unsupervised learning algorithm โดยมันจะมองหาตัวอย่างที่มีความคล้ายคลึงกันมากที่สุดเพื่อจัดกลุ่มข้อมูลตัวอย่างที่มีอยู่
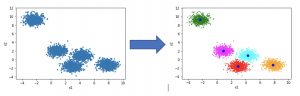
โดยการใช้ k-means model ต้องระบุค่าเริ่มต้นก่อนว่าต้องการที่จะจัดกลุ่มทั้งหมดกี่กลุ่ม ซึ่งปกติแล้วตัวเลขสามารถแบบออกได้เป้น 10 กลุ่ม (0-9) แต่เนื่องจากตัวเลขบางตัวสามารถเขียนได้หลายวิธี เช่น 4 7 2 และในการเอากลุ่มมาแยกประเภทแบบ classification ต้องมีกลุ่มมากกว่า classes ดังนั้นการจัด k-means ในกรณีนี้จึงแบ่งได้ 50 กลุ่ม เพื่อให้ครอบคลุมวิธีการเขียนที่หลากหลาย
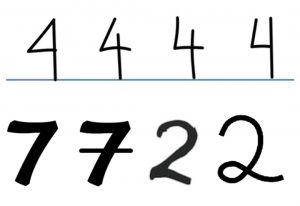
โดยหลังจากแบ่งข้อมูลออกเป็น 50 กลุ่มแล้ว แต่ละกลุ่มจะประกอบไปด้วย centroid หรือค่ากลางที่แสดงว่ากลุ่มนั้นๆมีค่าเท่าไหร่ ทำให้เหลือเพียงข้อมูล 50 ชุดข้อมูลจำนวนมากได้ในที่สุด แล้วจึงนำมาแยกประเภทด้วยเทคนิคต่างๆที่ใช้ใน supervised learning เช่น logistic regression model, artificial neural network, support vector machine หรือ decision tree
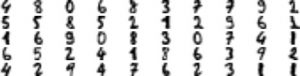
การประมวลข้อมูลจากฐานข้อมูลเพียง 50 ชุดอาจดูเป็นอะไรที่ไร้ประสิทธิภาพ แต่ K-means model เป็นการเลือกข้อมูล 50 ชุดที่เป็นตัวแทนข้อมูลจากฐานข้อมูลทั้งหมดจึงทำให้สามารถประมวลผลออกมาได้อย่างแม่นยำ โดยในหนังสือ Hands-on Machine Learning with Scikit-Learn โดย Keras, and Tensorflow สรุปไว้ว่า การคาดการณ์ด้วยข้อมูล 50 ชุดจากการจัดกลุ่มแบบ clustering algorithm มีความแม่นยำสูงถึง 92% ในขณะที่การเดาสุ่มข้อมูลมา 50 ตัวเพื่อประมวลผลนั้นมีค่าความแม่นยำอยู่เพียง 80-85%
อย่างไรก็ตาม เราสามารถเอา semi-supervised learning มาใช้ต่อได้ โดยหลังจากระบุว่าค่ากลางของแต่ละชุดข้อมูลที่ได้มานั้นมีค่าเป็นอะไร ก็สามารถเอาค่านั้นมาแทนที่ให้กับข้อมูลตัวอื่นๆในชุดนั้นได้ และทำให้ระบุได้ว่าข้อมูลหลายพันตัวจากฐานข้อมูลแรกนั้นมีค่าเป็นอะไรบ้าง
เทคนิคอื่นๆใน semi-supervised machine learning
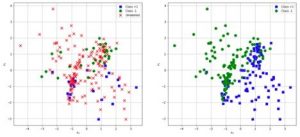
semi-supervised support vector machines (S3VM) เป็นอีกเทคนิคหนึ่งที่น่าสนใจ วิธีนี้ถูกนำเสนอที่ NIPS conference ในปี 1998 โดย S3VM เป็นเทคนิคที่มีความซับซ้อนมาก แต่หลักการโดยรวมแล้วไม่ต่างจากสิ่งที่เพิ่งพูดถึงไป โดย S3VM จะเอาข้อมูลที่ระบุค่าแล้ว (labeled) มาคำนวณเพื่อจำแนกประเภทของค่าที่ยังไม่ถูกระบุ และเอาข้อมูลที่สร้างขึ้นมานี้ในการประมวลผลต่อไป
ซึ่งหากสนใจเรื่องนี้ สามารถอ่านศึกษาข้อมูลเพิ่มเติมได้ที่ ในบทที่ 7 เรื่อง Machine Learning Algorithms
ข้อจำกัดของการใช้ semi-supervised machine learning
Semi-supervised learning ไม่สามารถเอามาใช้งานได้กับงานของ supervised learning ทั้งหมด เนื่องจากประเภทของชุดข้อมูลจะต้องสามารถถูกแบ่งด้วยการ clustering เหมือนในตัวอย่างการอ่านตัวเลขที่เขียนด้วยลายมือข้างต้น และสำหรับวิธี S3VM ต้องมีข้อมูลที่ระบุค่าได้จำนวนมากและครอบคลุมค่าหลักเพื่อที่จะนำไปประมวลผลต่อได้
ปัญหาคือ เมื่อข้อมูลมีความซับซ้อนมากและไม่สามารถระบุได้ ก็จะไม่สามารถใช้ semi-supervised learning ได้ ตัวอย่างเช่น เมื่อเราต้องการที่จะแบ่งภาพของสิ่งต่างๆจากหลายมุมมอง เราจำเป็นต้องมีข้อมูลที่ระบุค่าได้จำนวนมาก หมายความว่าหน้าที่การระบุค่าของข้อมูลรายตัวจะไม่หายไปในเร็ววัน
ถึงอย่างนั้น semi-supervised learning ยังสามารถนำไปใช้ได้ในอีกหลากหลายกรณี เช่น simple image classification และ document classification ซึ่งสามารถใช้การระบุค่าข้อมูลอัตโนมัติได้ Semi-supervised learning จึงเป็นเทคนิคที่มีประโยชน์มากหากเรารู้วิธีที่จะใช้งานมันในเวลาที่เหมาะสม
ที่มา: https://thenextweb.com/
แปลโดย: Pitsinee APS



{kind=link}
{kind=link}